
Iako sam u svojim tekstovima obrađivao razne teme, primetio sam da su ljudima uglavnom najkorisniji tekstovi u kojima sam opisivao zadatke sa testova i intervjua, što mi je veoma drago. Iz tog razloga ovu tradiciju nastavljam, prelazeći na sledeću veliku IT kompaniju – Google.
Google predstavlja svojevrsni Sveti Gral za mnoge programere, pa sam i ja odlučio da okušam svoju sreću sa njihovim procesom zapošljavanja. Međutim, sâm intervju se odigrao u relativno lošem trenutku – prijavu sam obavio još pre završetka prakse u Facebooku, ali mi je razgovor zakazan tek nakon što sam prihvatio ponudu da se tamo i vratim. Samim tim, intervjuu za Google nisam pristupio dovoljno ozbiljno, pa me je baratanje grafovima (treći zadatak) na kraju dotuklo. Svejedno, mislim da su ova dva intervjua bila dobra kako iz istraživačkog, tako i iz poznavanje-svojih-slabosti ugla.
Slede tri zadatka i njihova rešenja, kao rezultat tog “istraživanja”.
[linebreak /]
Dat je sortiran niz od N celobrojnih elemenata. Potrebno je prebrojati koliko se puta neki zadati broj pojavljuje.
Trivijalno rešenje je da se jednim prolazom kroz niz u linearnoj složenosti prebroje sva pojavljivanja ovog elementa. Avaj, sa takvim znanjem verovatno nećete proći intervjue, jer je ovo rešenje neefikasno. Pošto je niz sortiran, nameće se ideja da upotrebimo binarnu pretragu. Kada bismo proveravali da li neki element uopšte postoji u nizu, ovo bi se lako odradilo u logaritamskoj složenosti, ali naš zadatak je nešto teži, jer zapravo tražimo dužinu dela niza gde se ovaj element javlja.
Prvi način sa binarnom pretragom jeste da pronađemo traženi element, i da nakon toga iteriramo levo i desno od njega i prebrojimo pojavljivanja. Međutim, u najgorem slučaju ovaj pristup ima linearnu složenost, jer se može desiti da se u celom nizu nalazi samo taj element.
Ovo ćemo rešiti upotrebom nešto drugačije binarne pretrage koja traži poslednji element u nizu koji je strogo manji od X. Sa ovakvim algoritmom ćemo moći da nađemo krajeve intervala koji sadrži traženi broj X:
- da bismo našli početak intervala, pozvaćemo binarnu pretragu sa parametrom X, i kao njenu povratnu vrednost ćemo dobiti prvi element levo od podniza koji nas interesuje, pa njegov indeks jednostavno uvećamo za 1
- da bismo našli kraj intervala, pozvaćemo binarnu pretragu sa parametrom X+1, i povratna vrednost će predstavljati upravo kraj intervala
Ideja je veoma jednostavna, ali problem može predstavljati realizacija koju bi sigurno zatražili od vas na intervjuu, jer postoji dosta posebnih slučajeva na koje treba obratiti pažnju:
- Šta ako taj element ne postoji?
- Šta ako se podniz nalazi na samom početku niza?
- Šta ako se podniz nalazi na samom kraju niza?
Sledi C++ kôd koji uspešno rešava zadati problem.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | int countOccurancesInSortedArray(int *array, int len, int x) { // Special cases if (len == 0) { // Empty array return 0; } if (x < array[0] || x > array[len-1]) { // Number definitely not present in array return 0; } // Find the end of the interval int right = findLastElementSmallerThan(x+1, array, 0, len-1); if (array[right] != x) { // Element does not exist, since the end of the interval isn't X return 0; } // No need to go over the entire array, just left of the end of the interval // Also, if the array starts with X, the return index is -1 // We need to pass the appropriate parameters, i.e. "-1" and "right" int left = findLastElementSmallerThan(x, array, -1, right) + 1; // Result return right - left + 1;}int findLastElementSmallerThan(int x, int *array, int left, int right) { while (left < right) { int mid = (right == 0) ? 0 : (left + right) / 2 + 1; if (array[mid] >= x) { right = mid - 1; } else { left = mid; } } return right;} |
[linebreak /]
Dat je niz od N intervala na X-osi, gde je svaki interval zadat svojim celobrojnim početkom i krajem. Potrebno je naći najveći mogući podskup intervala tako da su oni u potpunosti sadržani jedan u drugom (svaki interval u potpunosti sadrži sve manje od sebe). Preciznije, ukoliko intervale u nekom podskupu posmatramo od najvećeg ka najmanjem, drugi interval mora da se nalazi unutar prvog, treći unutar drugog itd.
Kao babuške. Sort of.
U pitanju je zadatak iz dinamičkog programiranja. Ovaj koncept ćemo primeniti tako što ćemo za svaki interval pamtiti veličinu najvećeg podskupa u kojem je taj interval najmanji. Intervale ćemo sortirati prema njihovom početku, pa će neki interval moći da bude sadržan samo u intervalu koji se nalazi pre njega u nizu. Samim tim, nakon što neki interval obradimo (odnosno probamo da ga “ubacimo” u sve koji počinju pre njega) veličina najvećeg podskupa u kojem je on najmanji se više neće menjati.
Dakle, početna DP vrednost za sve intervale je 1 (podskup koji sadrži samo taj interval), i pri iteratiranju kroz intervale trenutni interval pokušavamo da ubacimo u podskup koji se završava nekim od prethodnih intervala. Nakon što obradimo sve intervale, imaćemo veličinu najvećeg podskupa.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | #include <algorithm>using namespace std;typedef struct interval { int begin; int end;} interval;bool cmp(interval a, interval b) { return (a.begin < b.begin);}int solve(vector<interval> arr) { // Sort by start int n = arr.size(); sort(arr, arr+n, cmp); // Initialize DP values vector<int> dp(n, 1); // Best solution int sol = 1; for (int i = 1; i < n; **i) { // Largest subset ending with this interval int currentBest = 1; for (int j = i - 1; j >= 0; --j) { // Try inserting it into another interval if (arr[i].begin > arr[j].begin && arr[i].end < arr[j].end) { if (dp[j] + 1 > currentBest) { currentBest = dp[j] + 1; } } } // Update the DP value and global solution dp[i] = currentBest; if (currentBest > sol) { sol = currentBest; } } return sol;} |
Složenost ovog algoritma je kvadratna. S obzirom da sam ovaj zadatak radio pre godinu dana, pomalo počinjem da sumnjam u optimalnost rešenja – ukoliko smislite bolji algoritam (npr. nlogn složenosti), ostavite komentar.
[linebreak /]
Posmatrajmo obilazak grafa gde se kreće iz nekog čvora, obilaze svi ostali čvorovi i vraća u početni čvor, ali tako da se svaka grana iskoristi tačno jednom. Kada je ovo moguće za proizvoljni graf? Koliko je najmanje grana potrebno dodati nekom grafu da bi ovo svojstvo bilo zadovoljeno?
U pitanju je veoma zanimljiv zadatak, jer je prvi deo smešan, dok drugi deo nije jednostavno primenjivanje nekog poznatog algoritma, već zahteva razmišljanje i računanje.
Prvo pitanje je čisto teorijsko – u pitanju je Ojlerov ciklus. Da stvar bude još smešnija, potrebno je jedno veoma jednostavno svojstvo da bi ovaj ciklus postojao, a to je da svaki čvor ima paran stepen.
A sada zanimljiviji deo pitanja: kako proizvoljan graf pretvoriti u graf sa Ojlerovim ciklusom? Za početak, primetimo da početni graf uopšte ne mora biti povezan. Ukoliko jeste, sigurno ćemo imati paran broj čvorova sa neparnim stepenom (jer zbir stepena svih čvorova u komponenti mora biti paran), pa problem lako rešavamo povezujući parove čvorova sa neparnim stepenom, odnosno sa N/2 grana, gde je N broj tih čvorova.
Ukoliko, pak, nije povezan, odnosno kada se sastoji iz više komponenti koje treba povezati, imamo dva zadatka:
- povezati komponente grafa
- “ukloniti” sve čvorove sa neparnim stepenom, odnosno dodati im grane
Možda vam je sada jasno da možemo ubiti dve muve jednim udarcem: ukoliko neke dve komponente imaju čvorove sa neparnim stepenom, treba spojiti upravo te čvorove, da ne bismo poremetili stepen nekih “ispravnih” čvorova. Nakon što to uradimo, ostaće nam nepovezane one komponente u kojima svi čvorovi imaju paran stepen, pa je očigledno da neke čvorove iz tih komponenti moramo da “žrtvujemo”, odnosno da nakačimo dve nove grane na njih, što nas najzad dovodi do sledeće taktike.
Komponente ćemo podeliti na dva tipa: one u kojima svi čvorovi imaju paran stepen i one koje imaju bar 2 čvora sa neparnim stepenom (podsetimo se da će broj tih čvorova biti paran). Prvi zadatak će nam biti da sve komponente spojimo u jednu, a to ćemo uraditi tako što ćemo ih poređati u zamišljeni krug i komponentu spojiti sa komponentom levo i komponentom desno od nje. Kako je u pitanju krug, ukupno će biti dodato K grana, gde je K broj komponenti. Pritom, kod komponenti prvog tipa obe grane ćemo nakačiti na isti čvor (da ne bismo poremetili parnost), dok ćemo kod komponenti drugog tipa grane nakačiti na dva čvora neparnog stepena.
Rezultat ovog postupka je da imamo jednu komponentu sa manjim brojem čvorova neparnog stepena – u svakoj komponenti drugog tipa smo “popravili” dva ovakva čvora, dok u komponentama prvog tipa ništa nije narušeno. Sada imamo samo jednu komponentu i paran broj čvorova neparnog stepena, pa je dovoljno da njih povežemo među sobom.
Najzad, izračunajmo koliko nam je grana to potrebno. Neka je:
- K – ukupan broj komponenti
- K’ – broj komponenti koje imaju čvorove neparnog stepena
- N – broj čvorova neparnog stepena
Broj grana je tada 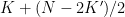
- Prvi sabirak predstavlja broj grana kojima spajamo komponente.
- Brojilac drugog sabirka je broj čvorova neparnog stepena (N) umanjen za broj čvorova koje smo popravili povezujući komponente (2K’).
- U drugom sabirku broj čvorova delimo sa dva, jer jednom granom popravljamo dva čvora.
Takođe postoji postupak pod nazivom “Ojlerizacija grafa“, ali on podrazumeva isključivo dupliciranje postojećih grana, bez dodavanja novih. Samim tim, ovaj postupak se ne može primeniti na nepovezane grafove, jer ne postoji način da se komponente povežu.
Hm, a ja ovde potpisujem neke confidentiality izjave za doticni intervju xD
A na glassdoor-u sve samo “signed an NDA and I’ll respect it” za google intervjue. Ili je bar tako bilo ranije
Double-checkovao sam, meni ništa nije pisalo za objavljivanje zadataka.
A kakav je format tih hangout intervjua? Koliko si ih imao i u kom vremenskom periodu? :)
Pod formatom mislim na koliko tehnickih pitanja po intervjuu :)
Google intervjui su u principu identični onima u drugi kompanijama, što je svojevrsni nezvanični industrijski “standard” – razgovor traje 45-60 minuta, a sastoji se iz kratkog upoznavanja i rešavanja nekoliko zadataka. Obično to budu dva zadatka, ali može biti i više ukoliko ih kandidat brzo reši.
U mom slučaju, to su bila dva intervjua na kojima sam imao ove zadatke, a razmak između njih je bio dve nedelje. U principu, nije potrebno puno vremena da bi se donela odluka o pozivu na sledeći intervju, ali su regruteri i komunikacija spori, tako da ume da se oduži.